背景
在前面两篇博客中写到 Redis 实现原子性的两种方式:事务、LUA脚本。在学习 LUA 脚本时,对 LUA 脚本能否完全保证redis的原子性做了分析,得出结论: LUA脚本保证原子性取决于Redis的部署架构,在单体和主从架构中是可以保证原子性的,但是在集群的分片部署中却不一定,也给出了解决方案。
提出问题
那么在主从架构和集群部署中,如何保证redis的消息不丢失?如何保证主从架构的一致性呢?
主从架构

高可用
Redis的主从架构使用的是 【一主多从】模式,且主从服务器采用的是【读写分离】的方式,即客户端只对主服务器进行读写,对从服务器读,最新数据由主服务器向从服务器进行同步
异步复制
Redis主节点每次收到写命令后,先写到内部缓冲区中,然后异步发送给从节点。主服务器收到新的写命令后会发给从服务器,但是主服务器不会等从服务器执行完命令后再返回结果给客户端,而是主服务器在本地执行完命令后不等从服务器返回结果直接返回客户端结果了。如果从服务器还没执行主服务器同步过来的命令,主从服务器之间的数据就会不一致了**。**
所以主从服务器的数据无法时时刻刻保持一致。
异步复制的三个阶段
先来看一下 Redis 官网对复制机制的描述
该段文字表述了,在主从复制过程中的三个过程机制
1.【基于TCP长连接的命令传播】,主从服务redis连接良好时,主服务器向从服务器传输命令。
2.【网络不稳定连接中断】,从服务器尝试重新连接主服务器,并获取在断开期间错过的命令
3.【首次同步】,主服务器使用bgsave命令生成子进程生成RDB文件【异步】发送给从服务器,从服务器收到RDB文件时清空当前数据后载入
总结
在首次连接同步阶段,从服务器获取主服务器的 RDB全量数据,连接过程中从服务器接收主服务器的写命令,连接过程若不稳定,从服务器请求错过的增量命令
注意
Redis复制在主端是非阻塞的,因为主服务端是生成一个子进程生成RDB文件异步发送给从服务器,这个子进程是 bgsave命令生成的
主从复制过程的原理
我先来搭建一个一主二从的redis结构
step1:创建一个replica文件夹, 然后将redis安装目录的bin文件中的内容复制到replica文件夹下的三个文件夹中,分别是master , slavel1, slave2
1 | cd /home/zqy/桌面/ |
step2:修改slave1 和 slave2的配置文件 ,redis.conf
1 | vim /home/zqy/桌面/replica/slave1/redis.conf |
step3:修改slave2的配置文件 ,redis.conf
1 | vim /home/zqy/桌面/replica/slave2/redis.conf |
step4:创建启动脚本 startup.sh
1 | cd /home/zqy/桌面/replica/master |
step5:启动脚本
1 | ./startup.sh |
注意:如果启动失败,可以进入 slave1和slave2文件夹中单独启动,启动语句是
1 | ./redis-server redis.conf |

从图中可以看出,因为创建主从redis都是在本机上进行的,所以ip不变,通过端口区分不同的redis服务器
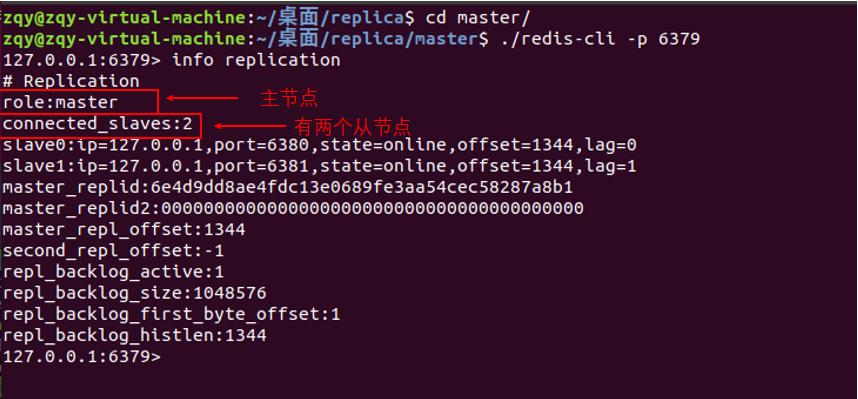
step6:进入主redis, 查看它的从节点们的信息,数量是否正确
1 | ./redis-cli -p 6379 |
主从首次连接的时候发生了什么
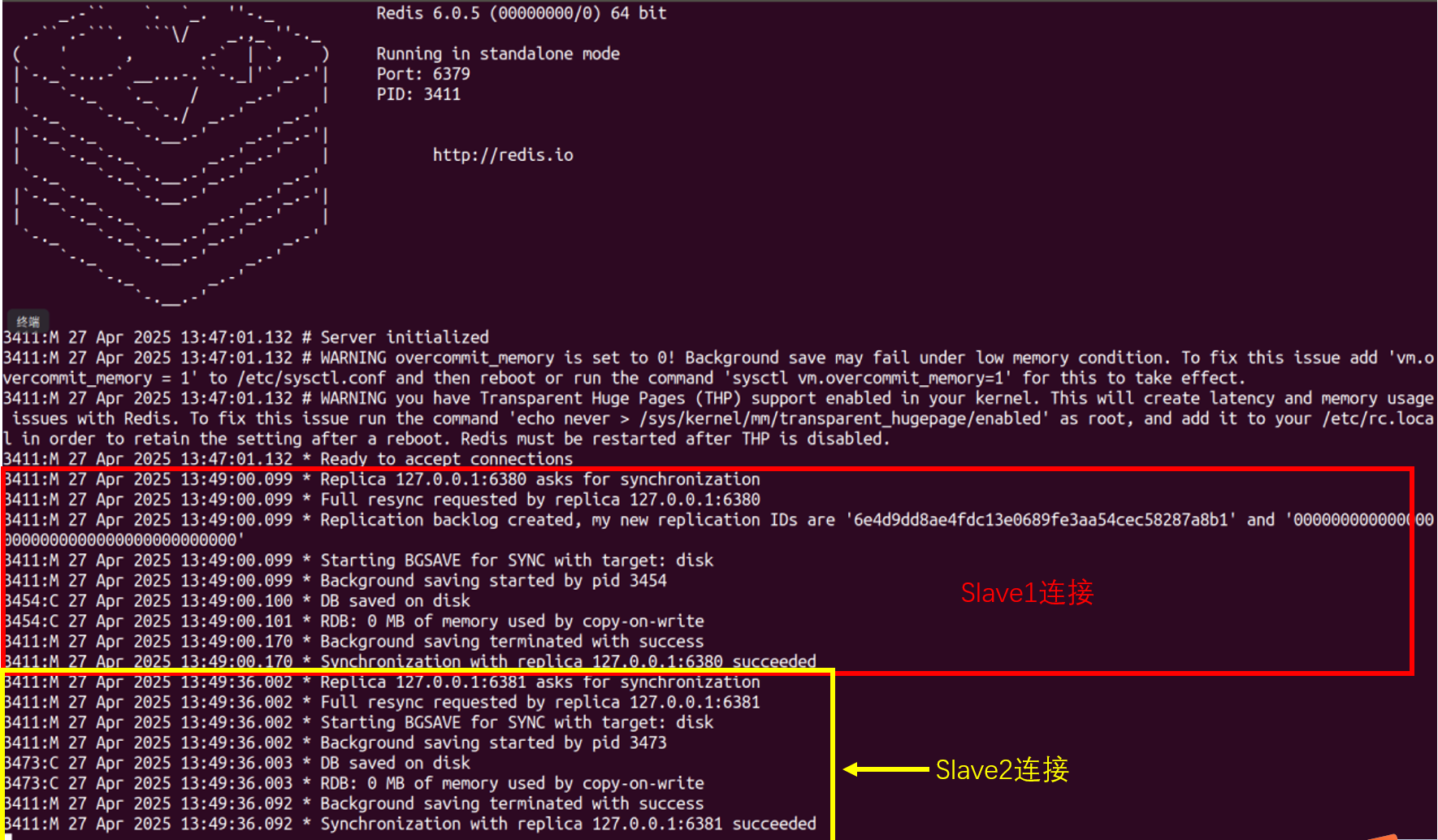
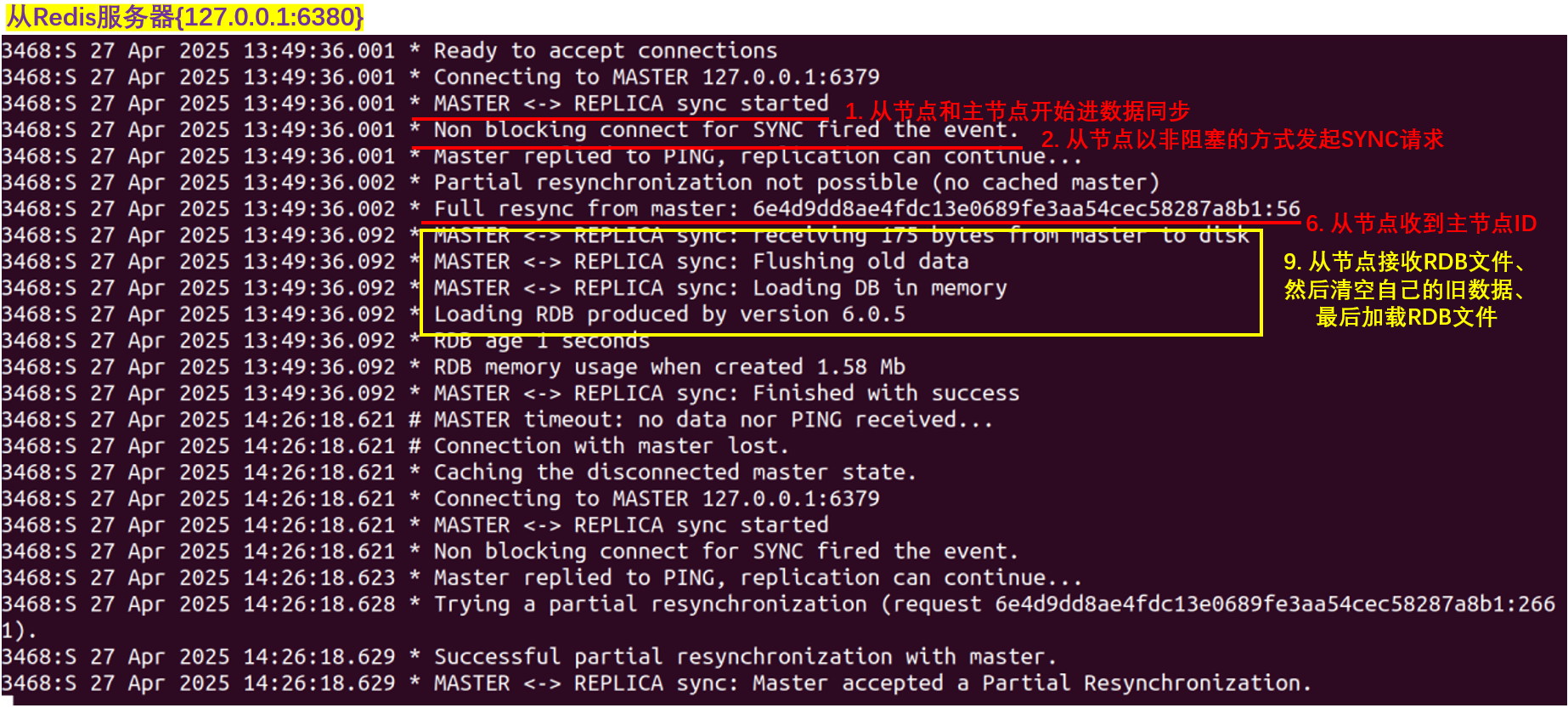

从实验中我们可以看到,当主从节点上线后,从节点会主动向主节点请求数据同步。
首先,从节点会向主节点发送 SYNC 命令请求数据同步,首次连接请求的时候会请求**全量数据**
然后,主服务器会给从服务器发送自己的 ID 的复制偏移量,目的是为了网络不稳定的时候能够让从服务器获取增量数据实现主从数据的一致
接着,主服务器会执行** BGSAVE 命令生成RDB**文件
最后,从服务器收到主服务器发来的RDB文件,它会**先将自己的存储清干净,然后再载入 RDB 数据**

主从连接断连的时候会发生什么
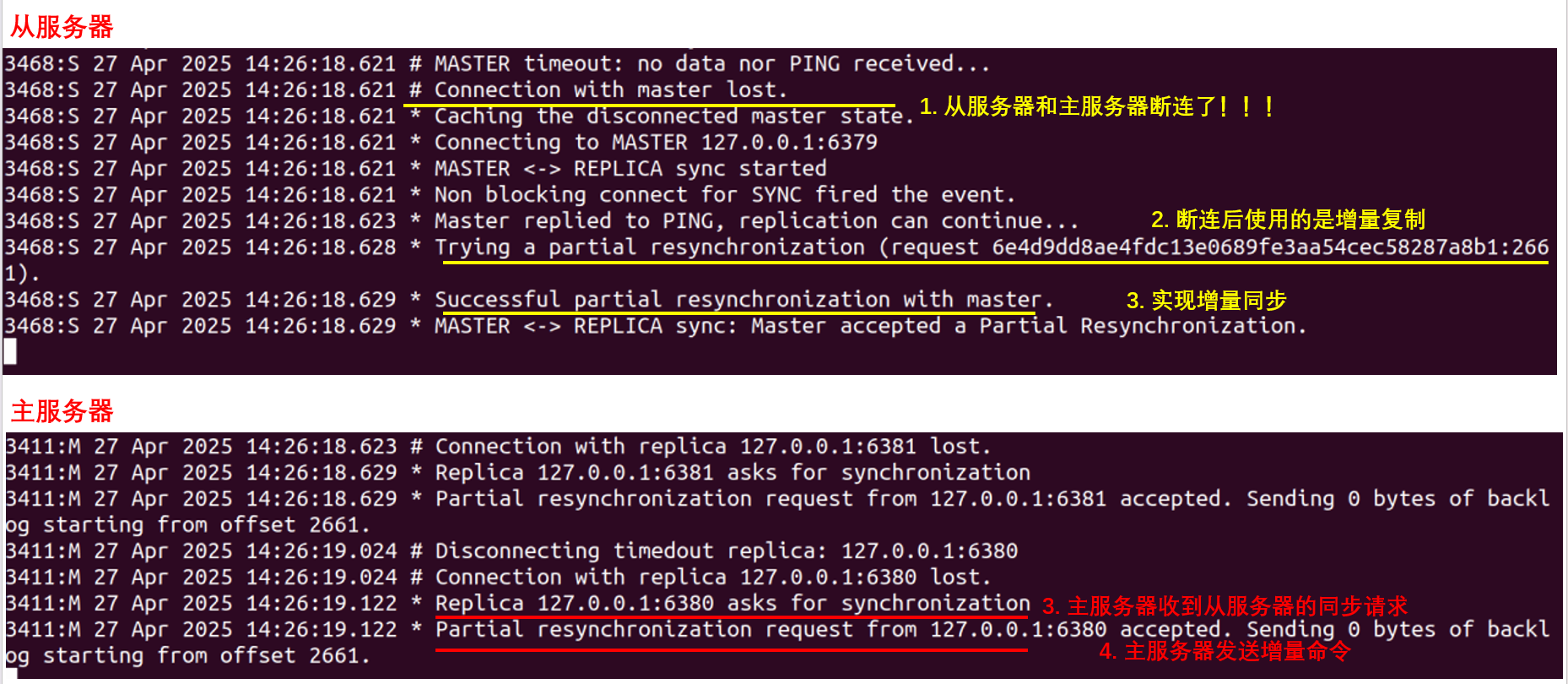
从这个实验中可以发现,并不是主从一断连的时候从服务器一定是请求主服务器实现全量复制。这是因为主从在首次连接的时候,主服务器给从服务器发送了他的ID和偏移量,主从断开连接的时候,从服务器会去ping主服务器,如果能ping通,说明主服务器没有掉线,因为从服务器保存了主服务器的ID和偏移量,尝试用增量补全数据会更高效。
如果是主服务器掉线了,那么主从服务器在断连又重连的时候,从服务器还是通过全量数据实现同步
集群分片架构
集群分片和主从架构的区别是,主从架构中主服务节点和从服务节点的数据是相同的,而集群中每个redis的数据是不同的,每个redis只负责一部分的数据槽。
为了防止集群中的单点故障,集群是包含主从架构的。
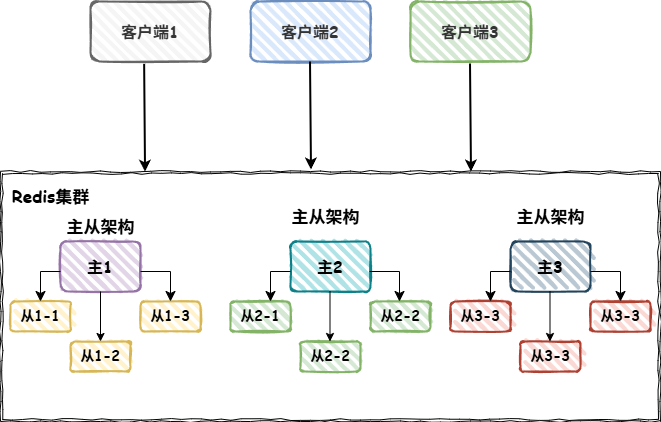
Redis 集群使用的是数据分片,一个集群包含16384个哈希槽,集群使用 CRC16(key)%16384计算key值属于哪个槽。上图集群中有3个主节点,所以该集群有3个哈希槽,例如
主1节点负责 0~5500号哈希槽
主2节点负责5501~11000号哈希槽
主3节点负责11001~16384号哈希槽
为了防止集群架构中出现单点故障,需要为每个redis主节点创建几个从节点,通过主从复制的方式保证当主节点故障时,还可以选举从节点作为新的主节点,让redis集群架构正常工作。不过如果主节点连同他的所有从节点都故障了,那么这个系统也可能会无法正常工作。
集群架构和主从架构一样,不能强保证数据的一致性
原因一
step1:客户端向主节点发送一个写命令
step2:主节点执行写命令,并向客户端返回命令的回复
step3:主节点将执行的命名发送给从节点实现数据同步
原因二
集群脑裂
客户端与主节点的网络连接正常,主节点和集群中的其它节点断连,导致哨兵以为主节点挂了,重新在从节点中选择一个作为主节点,当网络正常时会出现两个主节点,原先的主节点被降为从节点,然后旧主节点会向新的主节点请求同步数据,主从第一次同步数据,源主节点清空自己的数据接收新主节点发送的RDB文件,这会导致在网络断连期间新的操作命令丢失
集群脑裂的解决方式:当从节点发现主节点挂了后,应该禁止对主节点写操作
小结
| 维度 | 主从复制 | 集群分布式 |
|---|---|---|
| 数据分布 | 所有节点存储全量数据 | 数据分片存储,节点仅存储部分数据 |
| 扩展性 | 仅扩展读能力 | 扩展读/写能力和存储容量 |
| 一致性 | 异步复制,弱一致 | 分片内主从复制,弱一致 |