redis的数据结构
> string

先来看一下 Redis 的官方文档是怎么对 string 数据结构解释的:string 可以存储任何数据,包括二进制、文本、序列化等,限制是值不能超过512MB
string的底层数据结构
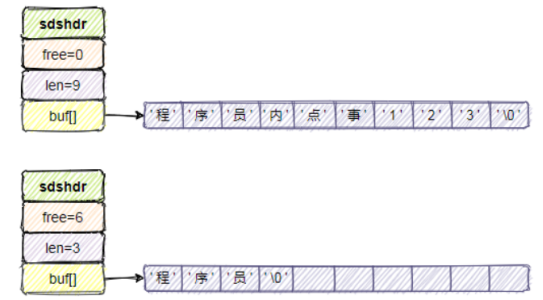
底层数据结构主要是 SDS(简单动态字符串)
1 | struct sdshdr{ |
- 使用SDS有更高的效率
C语言原生字符串中是不会保存字符串长度值的,获取字符串长度值就需要遍历一遍字符串,时间复杂度O(n)。SDS数据结构中有个变量单独保存了SDS字符串的长度,所以获取字符串长度的时间复杂度是O(1)。
- SDS采用了空间预分配策略
在SDS字符串增长时,先判断SDS数据结构中的free字段是否满足,若不满足,采用空间预分配扩展空间,不仅会为SDS分配修改所必要的空间,还会为SDS分配额外的未使用空间free,减少因为字符串增长而导致的空间重新分配次数的增加
- 惰性空间释放策略
在SDS字符串减小时,不直接回收内存,而是记录在free中,等待下次增长时直接使用
使用场景
作为缓存
可以缓存html页面、对象等常规计数(适用于计算访问次数、点赞、库存数量等)
INCR:将字符串的值解析为整数,并且+1
DECR:将字符串的值解析为整数,并且-1
INCRBY:将字符串的值解析为整数,并且+指定增量
DECRBY:将字符串的值解析为整数,并且-指定增量分布式锁
string 的 SETNX命令可以实现分布式锁
SETNX 命令
1 | SET lock_key unique_value NX PX 1000 |
- key 不存在时,插入成功, 加锁成功
- key 存在时,插入失败,加锁失败
NX :lock_key 不存在时,执行成功
PX :lock_key 的过期时间
unique_value : 客户端唯一标识
> List
Redis 的官方文档对 List 数据结构解释:List 是一个按照插入顺序排序的字符串列表(是链表不是数组),这个列表实现了栈和队列的特性
使用场景
- 消息队列
消息队列对消息的存取要满足消息的有序性,list 对链表的头尾操作满足了消息有序性的存储和消费 - 记住用户在社交网络上发布的最新动态
常用命令
LPUSH:list队头添加新元素
RPUSH:list队尾添加新元素
LPOP:从队头取元素
RPOP:从队尾取元素
BLPOP:阻塞式从队尾取数据,因为消费者往队尾放一个元素时没有通知消费者取,需要消费者不停地调用LPOP从队头取数据,这样就会空耗CPU,使用BLPOP命令没有读到数据时,消费者自动阻塞释放CPU,直到队列中有数据时再读新数据
为什么Redis 的 list 数据结构使用链表
- 即使 list 中的数据量非常大,也能保证在队头和队尾进行数据存储的时候时间复杂度是O(1)
- 但是链表在查询的时候时间复杂度要高于数组,数组通过索引下标就可以直接访问数据了,那为什么不用数组呢?这是因为对于数据库来说,快速将数据插入到较长的 list 数据结构中是更加重要的

SET

Redis 的官方文档对 SET 数据结构解释:SET 是一个无序且键值唯一的集合
使用场景
- 执行常见的集合操作,差集、并集、交集等(点赞机制、共同关注等)
常用命令
SADD:添加元素到集合中
SREM:从集合中删除指定成员
SISMEMBER:查看集合中是否存在查找的元素
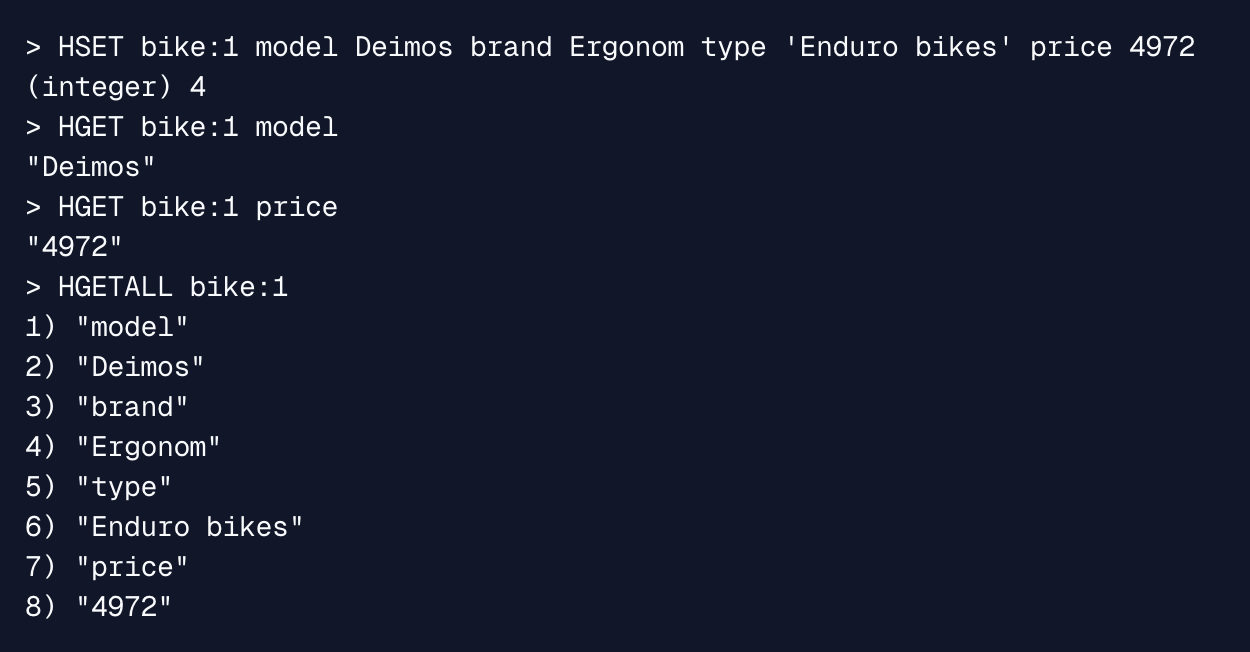
HASH

Redis 的官方文档对 HASH 数据结构解释:HASH 是键值对的集合
使用场景
- 存储对象
- 存储计数器分组
常用命令
HMSET:设置 hash 字段
HGET:返回给定字段的值

sort sets
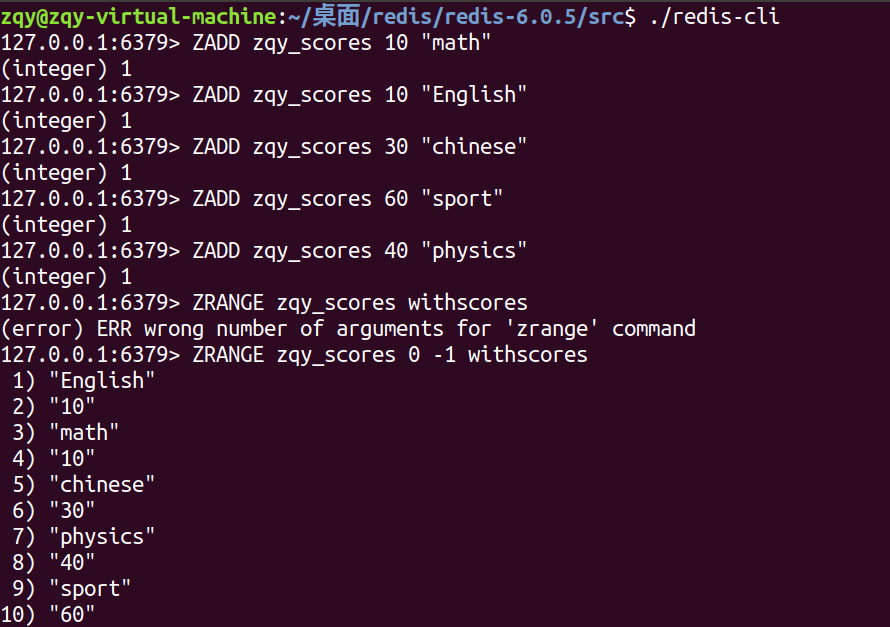
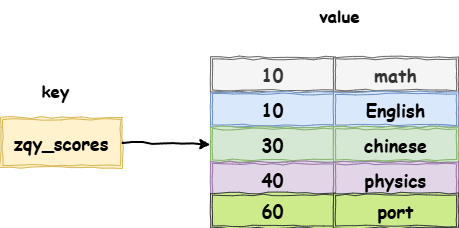
Redis 的官方文档对 sort sorts 数据结构解释:sort sorts 关联了一个分数排序,每个value至少有两个元素,一个是排序值,另一个是元素值,当排序值相同的时候,按照元素值的字典序进行排序
使用场景
需要对唯一元素进行排序的场景
- 排行榜
- 姓名按照字典序排序
常用命令
ZADD:在有序集合中添加元素(需要额外设置排序分数)
ZSCORE:查看某个元素的排序值
ZREVRANGE:查找排序在某个区间的元素
bitmaps

Redis 的官方文档对 bitmap 数据结构解释:bitmap 是一连串的二进制数组,按位进行操作
使用场景
- 数据量大且需要节省数据空间的场景
- 二值状态统计的场景,例如打卡签到
常用命令
SETBIT:设置位为1或0
GETBIT:获取位的状态
BITPOPS:查找某个key某个区间指定为0或1的第一个位置