背景
在字节一面中,面试官给了一个深度分页的sql语句,给出优化方案,当时没有回答出来,面试后查询各种资料,终于理解了深度分页对mysql性能的影响,并且自己也做了一个小实验,理解了深度分页的原因以及它的优化方案。
limit 查询
limit 是查询语句的子句,用来限制查询结果的行数,配合 offset 实现分页查询
limit 的语法
1 | select colum1,colum2...from table where “条件语句” limit [offset] [Row_count]; |
上面这条查询语句的作用是:查询满足条件的记录,只显示从偏移量为[offset]开始的往下的Row_count条记录。
mysql架构
当offset 很大时,为什么会影响 mysql 的性能呢?为了了解这个问题,首先必须要知道 mysql 的查询架构。
mysql 的架构主要分为两层,分别是 server 层 和 存储引擎层
server层
· 解析器:解析sql语句的词法、语法,生成语法树
· 预处理器:如果有 * 就展开所有列,检查数据表和字段是否存在
· 优化器:mysql 会根据查询语句以及索引结构选择一个最高效的查询方式
· 执行器:和存储引擎交互,存取数据
存储引擎层
存储mysql的数据,mysql 默认使用的存储引擎是 innoDB ,而 innoDB 对聚簇索引和二级索引的组织结构都是 B+ 树
借鉴一下小林coding 网站中对“mysql查询一条数据的过程”的描述图
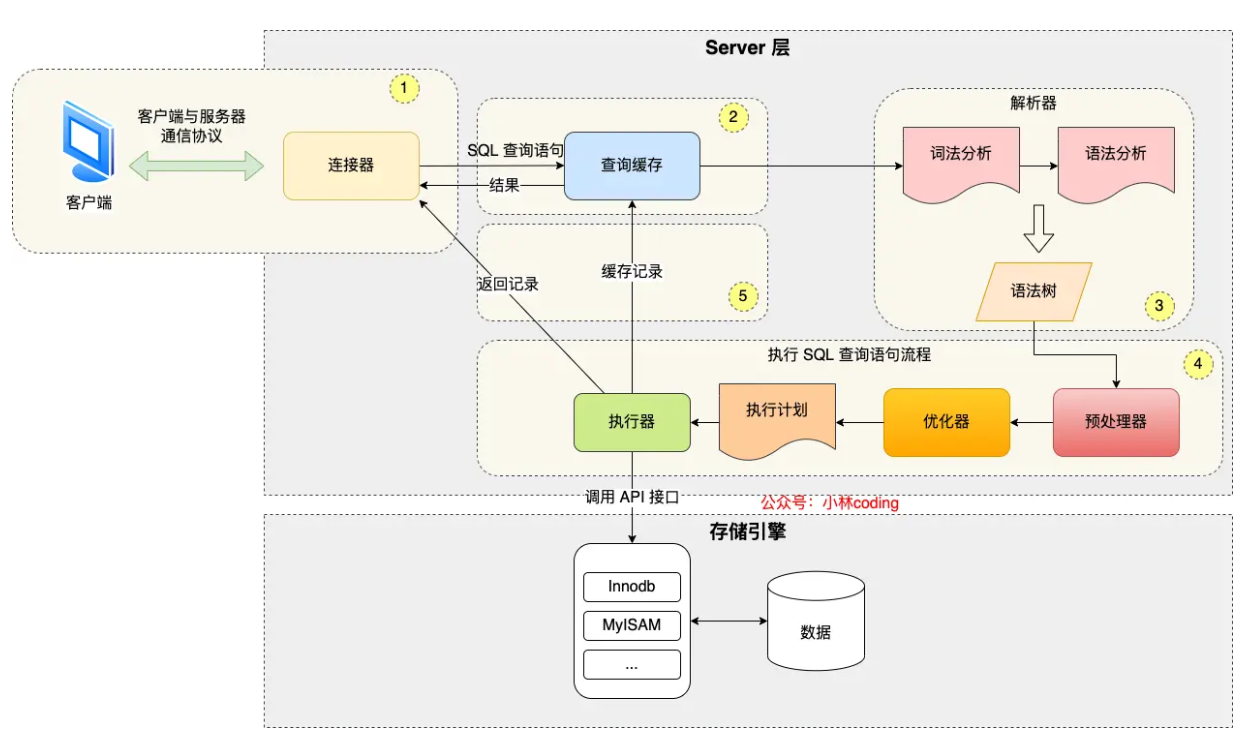
limit 的实现是在server层
· 如果limit没有搭配 offset, 执行器读取到 Row_count条记录后就会停止读取过程
· 如果limit搭配了 offset, 执行器会跳过前面 offset 行数据,然后继续读 Row_count行数据后停止
mysql的索引查询
在讨论limit分页降低mysql查询时,需要先了解 mysql 的查询过程
mysql的存储引擎默认使用的是 innoDB , innoDB 索引结构默认使用的是B+树,B+ 树是一个矮胖的结构,且天然支持二分查找,能够保证即使 mysql 中数据量很大的情况下,也能通过 3~4次的I/O 查询查到数据。
创建一个数据表,show table看一下表结构如下

聚簇索引(主键索引)
可以看到主键索引是 id 列
在mysql中,主键索引的数据结构是 B+ 树,结构特点是非叶子结点值都是索引,叶子结点值包含了所有数据
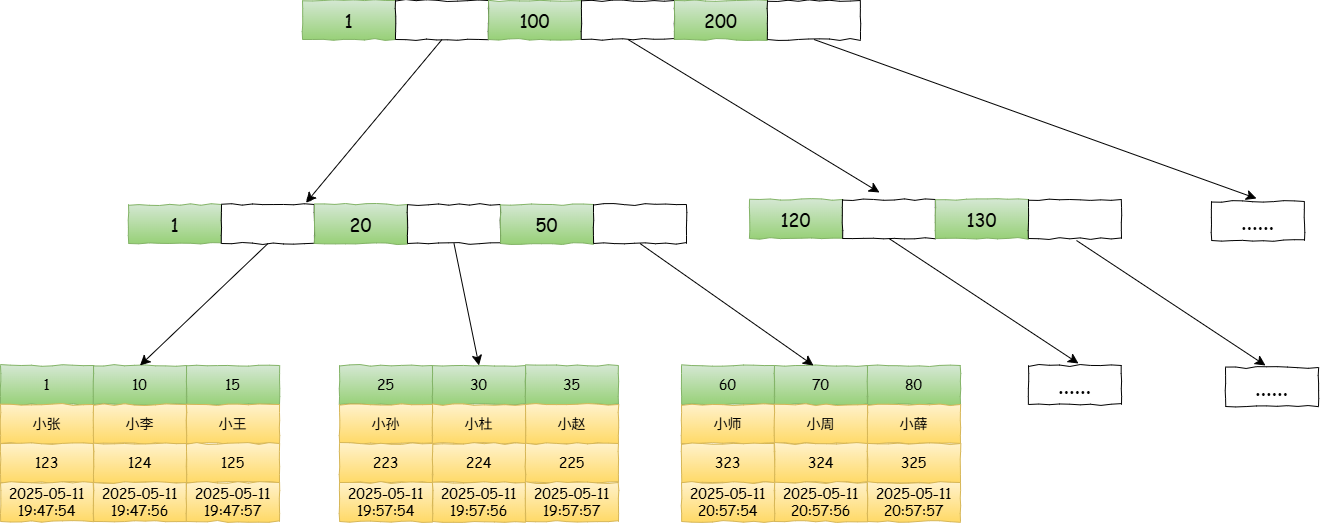
二级索引(非唯一索引)
可以看到二级索引是number
在mysql中,二级索引数据结构也是 B+ 树,结构特点是非叶子结点值都是二级索引, 叶子结点值存的是二级索引值+ 主键

回表
因为主键索引的叶子结点中,存放了所有的数据,而二级索引的叶子结点中存放的只有 二级索引+主键值。所以当使用二级索引为条件查询时,且查询的数据不只是主键索引值,那么就需要先扫描二级索引树找到主键索引,然后拿着主键索引值去主键索引树中查询,这个过程就叫回表,也就是需要两次扫描索引树才能查到最终的值。
例如: select * from table_name where number_id = 123;

limit 耗时分析
前面介绍了mysql的架构以及依据索引查询的过程,分析select * from table where “条件” limit 1000000,10分析
· 虽然只返回10行数据,但是 innoDB 实际上扫描了1000010行数据,server 层的执行器在执行sql语句时,innoDB 会返回 server层记录,sever层检查该记录是否是1000000后面的记录,如果不是就丢弃,如果是就返回给客户端。显然,该条语句实际上读了很多无用的数据,在这个过程当可能经历了1000000次无用的回表
·server层在执行语句的时候,会有一个优化器,mysql会判断当前的执行方案是否高效,当offset很大时,也可能会回表,那么mysql会放弃这种方式干脆用全表扫描,而全表扫描就是最慢的操作。
实验测试一下
创建一个数据表, 表名 large_data
1 | -- 创建表 |
插入100万条数据
1 | -- 使用存储过程插入数据 |
先把二级索引删除,整张表只有 主键索引
offset 不同对查询有什影响?
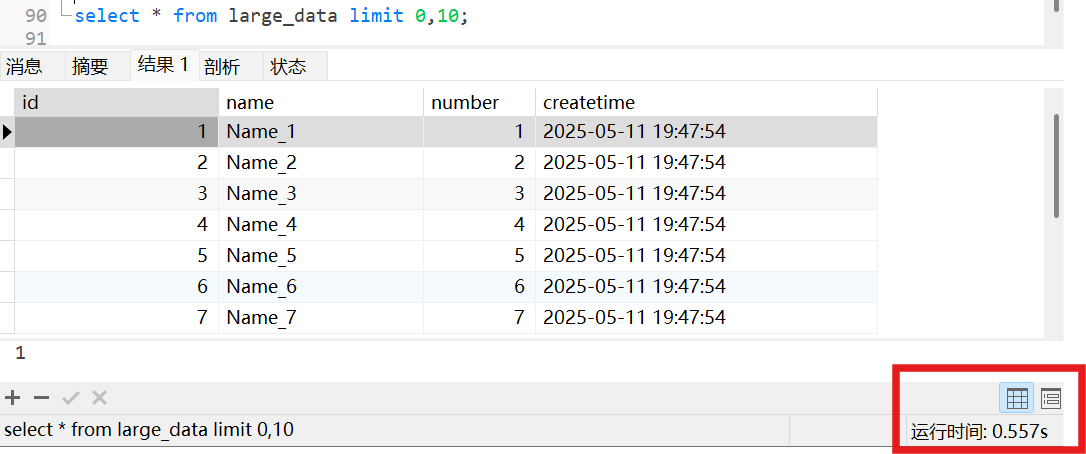
1 | explain select * from large_data limit 0,10; |
1 | explain select * from large_data limit 1000000,10; |


可以看出这两条语句走的是全表扫描,这是因为查询语句中查询的是 所有列,且没有where 索引列作为查询条件。全表扫描时,对于第一条语句,执行扫描了10条记录就停止扫描,而第二条语句中,执行扫描1000010条语句才停止执行,所以第二条语句执行的时间是要多于第一条语句执行的时间的。
所以,在查询的时候需要考虑是否真的要查询所有列
在这张表上对number加上普通索引
1 | CREATE INDEX index_number ON large_data (number); |
然后执行下面的语句
1 | select * from large_data where number>1000000 limit 5000000,10; |
看一下执行计划
1 | explain select * from large_data where number>1000000 limit 5000000,10; |

可知这张表走的是二级索引,因为查询的是所有列,查询走的是二级索引,所以会先查询二级索引获得主键值,再通过主键值查询主键索引,通过主键索引的叶子结点返回查询的所有列。这条查询是查询5000010条记录,丢弃前面的5000000条数据,只返回最后10条数据。所以前面的5000000条数据都是不必要的。
从底层原理来看,数据库中的索引节点和数据节点都是存储在磁盘上的,每访问一个B+ 树节点都会产生一次 I/O操作,磁盘的速度很慢,当查询大量无效的数据,访问磁盘的次数就越多,耗时也就越多。
当产生大量的无效的回表查询时,耗时竟然比全表扫描还要多!
large_data表中,id是主键索引, number 是二级索引
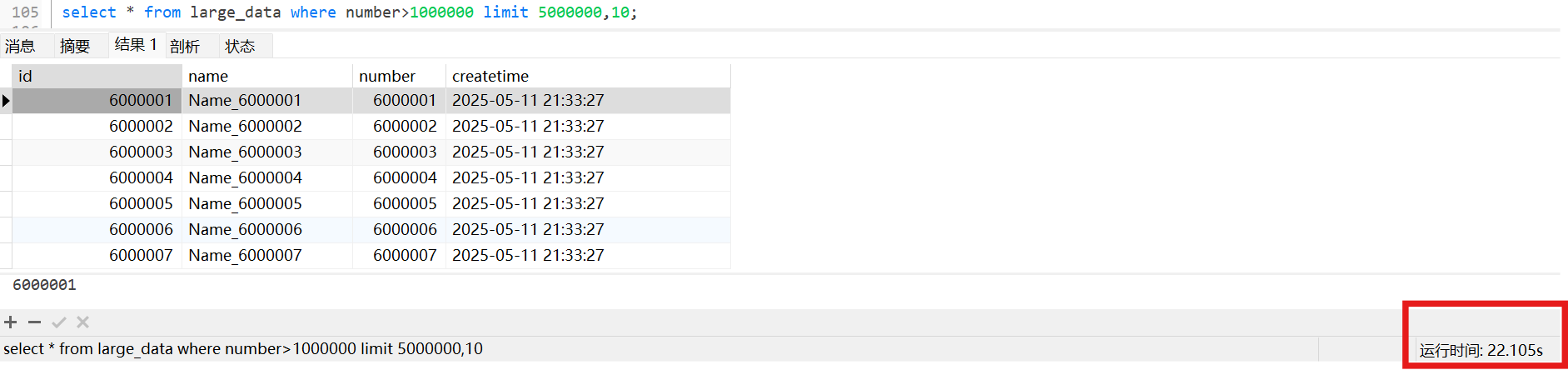

large_data表中,只有id是主键索引,没有二级索引
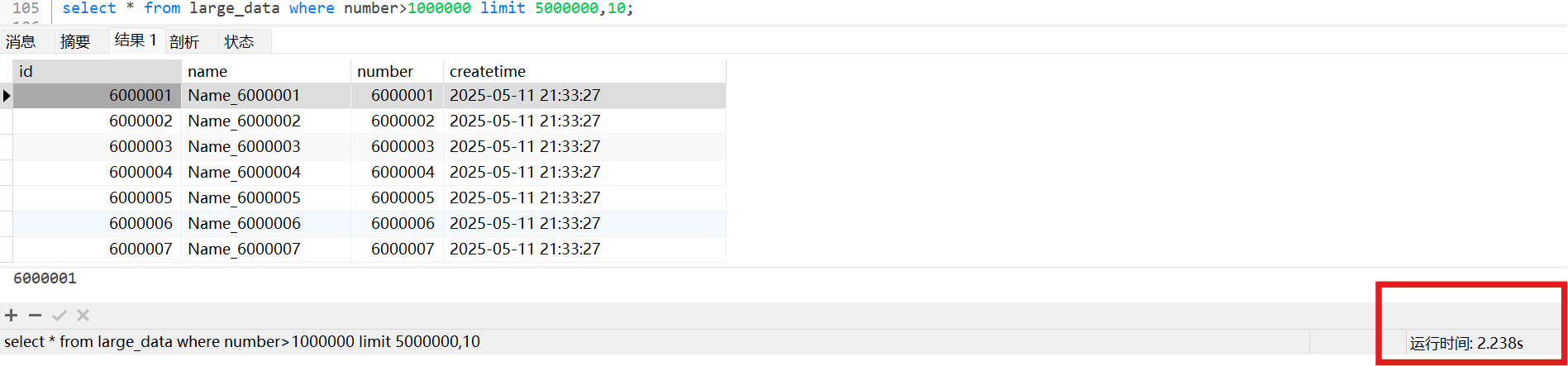

如何减少回表次数?
因为大量的耗时在无效的回表,那么减少回表次数就能够降低耗时,那么如何降低回表次数呢?
使用内连接(inner join)
可以使用子查询减少 offset 的影响
1 | select * from large_data t1 inner join (select id from large_data where number>1000000 LIMIT 5000000,10) as t2 on t1.id=t2.id; |
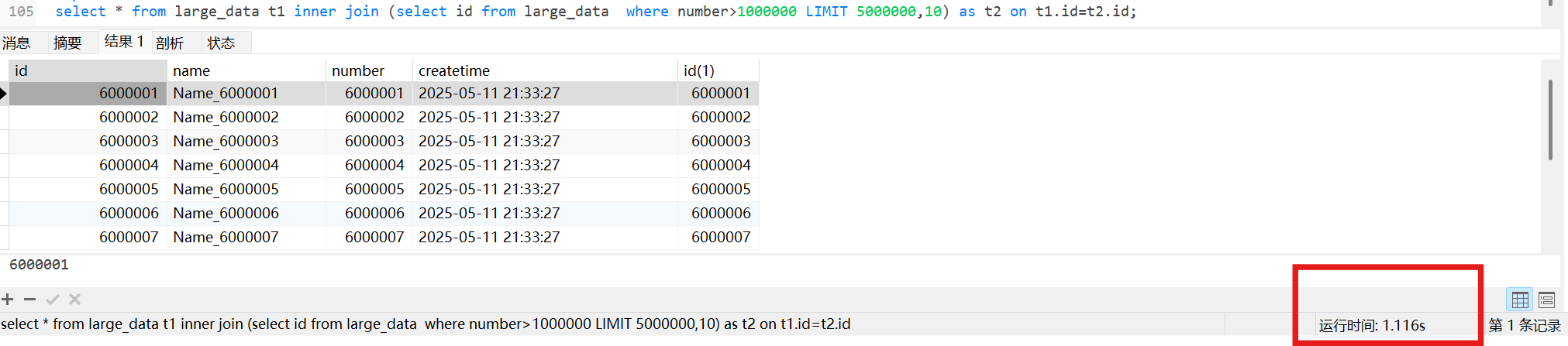
看一下执行计划
1 | explain select * from large_data t1 inner join (select id from large_data where number>1000000 LIMIT 5000000,10) as t2 on t1.id=t2.id; |

思想:通过二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这个过程并没有回表操作,直接走的是主键索引
使用子查询
1 | select * from large_data where id >= (select id from large_data where number>1000000 limit 5000000,1) LIMIT 10; |
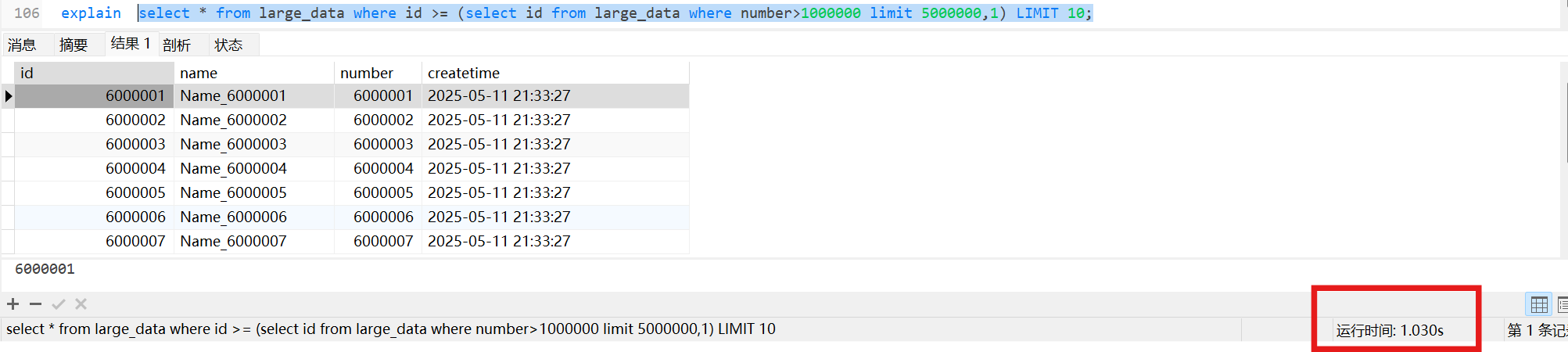
看一下执行计划
1 | explain select * from large_data where id >= (select id from large_data where number>1000000 limit 5000000,1) LIMIT 10; |

执行该语句避免了无效的回表,子查询中通过查询二级索引获得主键索引,然后直接根据子查询的主键索引在聚集索引中查询,根据第一查询的主键的值往后再查10个就可以了。
使用索引覆盖
如果查询的不是所有列,如果查询的是主键列可以直接查询主键索引,也可以通过二级索引直接查询主键索引,如果查询多个列,也可以创建联合索引
例如: select id , number from large_data where number > 1000000 limit 5000000,10;
总结:如何避免 limit 深度分页导致mysql 性能变差?
避免limit深度分页导致mysql性能变差的核心思想是减少不必要的回表,从底层存储原理来看,回表操作包含多次的I/O,而磁盘I/O是很耗时的
- 使用子查询,将查询条件转移到主键索引树
- 使用inner join 内联查询,将查询条件转移到主键索引树
- 使用覆盖索引,避免回表,但这个是不是适用所有的深度分页,它根据查询的列来判断,如果只查主键索引,可以使用主键索引,如果查询多个列,可以创建联合索引